NeurIPS 2023 Tutorial:
Latent Diffusion Models:
Is the Generative AI Revolution Happening in Latent Space?
Date, Time, Location: Monday, December 11, 2023, 9:45am-12:15pm
New Orleans Ernest N. Morial Convention Center, Hall E2
New Orleans Ernest N. Morial Convention Center, Hall E2
📢 Check this Google drive link for our tutorial slides.
Overview
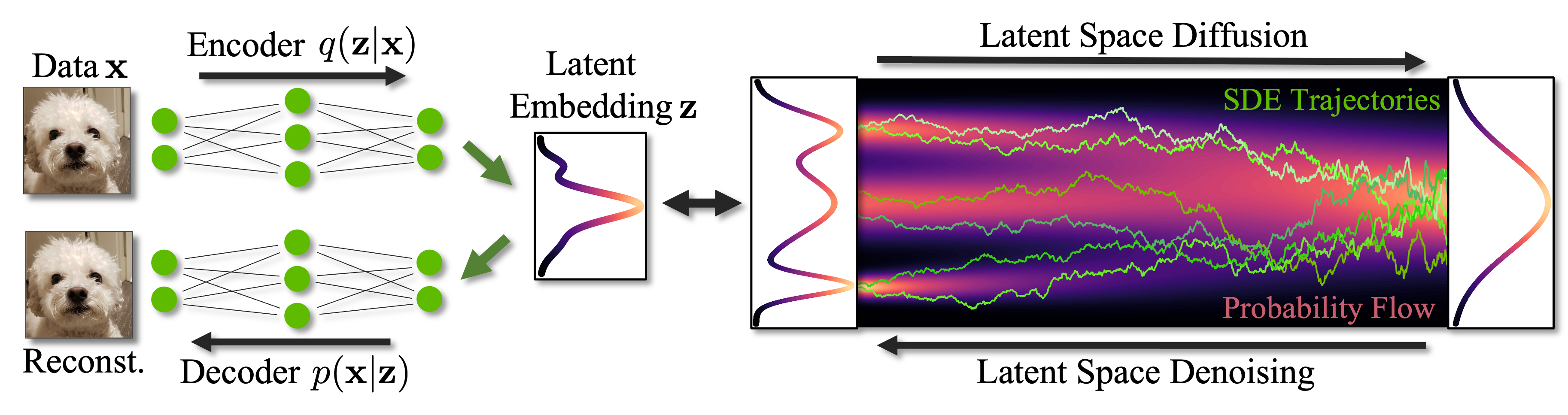
Diffusion models have emerged as a powerful class of generative models and demonstrated astonishing results, in particular in image synthesis. However, training high-resolution diffusion models in pixel space can be highly expensive. Overcoming these limitations, Latent Diffusion Models (LDMs) first map high-resolution data into a compressed, typically lower-dimensional latent space using an autoencoder, and then train a diffusion model in that latent space more efficiently. Thereby, LDMs enable high-quality image synthesis while avoiding excessive compute demands. Furthermore, the LDM paradigm with an autoencoder, which can be tailored to specific problems and data, and a separate diffusion model in latent space offers significant flexibility with respect to architecture and model design. This has allowed LDMs to be successfully extended to various tasks beyond image generation, such as video synthesis, 3D object and scene generation, language modeling, and more. Most prominently, the well-known text-to-image model Stable Diffusion leverages the LDM framework. LDMs have become very popular and widely used in the generative modeling literature.
In this tutorial, we aim to provide an introduction to LDMs. While the literature on diffusion models has become broad, the LDM paradigm stands out as a particularly powerful approach due to its flexibility and excellent trade-off with respect to performance and compute demands. We aim to present a tutorial on LDMs that will benefit researchers interested in efficient and flexible, yet expressive generative modeling frameworks. We will also highlight advanced techniques for accelerated sampling and controllability, and discuss various applications of LDMs beyond image synthesis. Moreover, a panel discussion will provide diverse perspectives on this dynamic field and offer an outlook for future research on LDMs.
This tutorial focuses specifically on latent diffusion models. For general tutorials on diffusion models, we would like to refer to the tutorials presented at CVPR'22 and CVPR'23, which are recorded and publicly available.
Speakers
Schedule
| Title | Speaker | Time (CST) |
|---|---|---|
| Part (1): Introduction to Latent Diffusion Models Diffusion models, autoencoding, compression, latent diffusion, architectures, image generation |
Karsten Kreis | 09:45 - 10:25 |
| Part (2): Advanced Design and Controllability End-to-end training, maximum likelihood, accelerated sampling, distillation, control and editing |
Arash Vahdat | 10:25 - 11:05 |
| Part (3): Latent Diffusion Models beyond Image Generation Video generation, 3D object and scene synthesis, segmentation, language & molecule generation |
Ruiqi Gao | 11:05 - 11:45 |
| Part (4): Panel Discussion | 11:45 - 12:15 |
Panelists




Google Deepmind

University of California, Los Angeles
About Us

Karsten Kreis is a senior research scientist at NVIDIA's Toronto AI Lab. Prior to NVIDIA, he worked at D-Wave Systems and co-founded Variational AI, a startup utilizing generative models for drug discovery. Karsten is trained as a physicist and did his Ph.D. at the Max Planck Institute for Polymer Research. Currently, Karsten’s research focuses on developing novel generative learning methods, and on applying deep generative models in areas such as computer vision, graphics and digital artistry, as well as in the natural sciences. Karsten has worked on diffusion models and latent diffusion models for image, video, texture, geometry, and 3D scene synthesis.

Ruiqi Gao is a senior research scientist at Google Deepmind. Her research interests are in statistical modeling and learning, with a focus on generative models and representation learning. She received her Ph.D. degree from the University of California, Los Angeles (UCLA) in 2021 advised by Song-Chun Zhu and Ying Nian Wu. Her recent research themes include scalable training and inference algorithms of deep generative models, such as diffusion models and energy-based models, and their applications in compute vision and natural science areas. Ruiqi has worked on diffusion models and latent diffusion models for image and video generation.

Arash Vahdat is a principal scientist and research manager at NVIDIA Research where he leads the fundamental generative AI team. Before NVIDIA, he was a researcher at D-Wave Systems, working on generative learning and its applications in label-efficient training. Before D-Wave, Arash was a research faculty member at Simon Fraser University, where he led computer vision research and taught master courses on machine learning for big data. Arash’s current area of research is focused on generative learning with applications in multimodal training (vision+X), representation learning, 3D generation, and gen AI for science. Arash has worked on latent diffusion models for images, text, 3D data, semantic segmentation, and inverse problems.